Автор: Брайан МакБрайд
Дополнено: Даниэлем Бусби и Крисом Долином
Оригинал: http://jena.sourceforge.net/tutorial/RDF_API
Данная статья опубликована с любезного разрешения компании HP
Предисловие
Это руководство знакомит читателя как с Resource Description Framework (RDF) консорциума W3C, так и Java API для RDF — Jena. Оно преднозначено для программистов, которые не знакомы с RDF, и которые предпочитают осваивать новые технологии разрабатывая прототипы, или, по разным причинам, стремятся как можно быстрее приступить к реализации. Предполагается определенное знание как XML, так и Java.
Попытки использования новой технологии слишком быстро, без должного понимания модели данных RDF приводит к неудаче и разочарованию. В то же время изучение модели данных — не слишком веселое занятие и, часто ставит в тупик. Наиболее эффективный путь — это параллельное изучение модели данных и способов ее использования. Познакомьтесь с определеным аспектом модели данных и тутже попробуйте новое знание на практике. Затем освойте другой аспект, и опять опробуйте его в деле. В таком случае теория подкрепляется практикой, а практика — теорией. Модель данных RDF — довольно проста, так что такой подход не потребует слишком много времени.
RDF выражается в синтаксисе XML, и те, кто знаком с XML могут думать об RDF в терминах XML. Это ошибка. RDF нужно понимать в терминах его модели данных. Данные RDF могут быть представлены в форме XML, но понимание синтаксиса — вторично по отношению к пониманию модели данных.
Реализация Jena API, включая исходные тексты для всех примеров использованных в этом руководстве можно заурузить с сайта Jena http://jena.sourceforge.net/downloads.html.
Содержание
Введение
Resource Description Framework (RDF) — это стандарт (формально — Рекомендация W3C) для описания ресурсов Что такое ресурс? Это довольно сложный вопрос и точное определение этого понятия — все еще предмет обсуждения. Для наших целей мы можем рассматривать ресурс как нечто, что мы можем идентифицировать. Вы — ресурс, также как и ваша домашняя страничка, это руководство, число один и большой белый кит из «Моби Дика».
Примеры в этом руководстве будут о людях. Они используют RDF представление VCARDS. легче всего представить себе RDF в форме диаграм из узлов и дуг между ними. Простая vcard может выглядить примерно так:

Глоссарий Ресурс, John Smith, показан в виде эллипса и идентифицирован с помощью Унифицированного Идентификатора Ресурсов (URI)1, в данном случае «http://…/JohnSmith». Если вы попробуете пройти по этому адресу используя ваш броузер, маловероятно, что вы преуспеете; наверно вы бы удивились, если бы ваш броузер смог доставить Джона Смита вам на десктоп. Если вы не знакомы с концепцией URI, думайте о них просто, как о, немного странно выглядящих, именах.
Ресурсы имеют свойства. В этих примерах нас будут интересовать свойства которые могут появиться на бизнес карточке Джона Смита. Рисунок 1 демонстрирует только одно свойство — полное имя Джона Смита. Свойство представляется в виде дуги, помеченной именем свойства. Имя свойства — тоже URI, так как URI довольно длинные и громоздкие диаграмма показывает их в форме XML qname. Часть до ‘:’ — называется префиксом пространства имен и представляет пространство имен. Часть после ‘:’ — называется локальное имя и представляет имя внутри пространства имен. Свойства обычно представляются в форме qname, когда записаны как RDF XML, так что это удобное сокращение для использования на диаграммах и в тексте. Одноко, строго говоря, свойства идентифицируются с помощью URI. Форма nsprefix:localname — сокращение для URI пространства имен соединенного с локальным именем. Не существует требования, чтобы URI свойства разрешался во что-нибудь доступное браузером.
Каждое свойство имеет значение. В данном случае значение — это литерал, который пока что мы можем рассматривать как стрку символов 2. литералы показываются как прямоугольники.
Jena — это Java API, которое можно использовать для создания и манипулирования RDF графами, подобными этому. Jena имеет классы для представления графов, ресурсов, свойств и литералов. Интерфейсы представляющие ресурсы, свойства и литералы называются Resource, Property и Literal соответственно. В Jena граф называется модель и представлен интерфейсом Model.
Код для создания этого графа, или модели, прост:
// некоторые определения
static
String personURI =
"http://somewhere/JohnSmith"
;
static
String fullName =
"John Smith"
;
// создание пустой Модели Model model = ModelFactory.
createDefaultModel
(
)
;
// создание ресурса Resource johnSmith = model.
createResource
(personURI
)
;
// добавление свойства johnSmith.
addProperty
(VCARD.
FN, fullName
)
;
Он начинается с определения нескольких констант, и затем, с помощью метода createDefaultModel() класса ModelFactory в памяти создается пустая модель. Jena содержит и другие реализации интерфейса Model, например реализацию, которая использует реляционную базу данных: такие типы Model также доступны с помощью ModelFactory.
Затем создается ресурс Джона Смита, и к нему добавляются свойства. Свойства предоставляются «константным» классом VCARD, который содержит объекты представляющие все определения в схеме VCARD. Jena также предоставляет константные классы для других, широко распространенных, схем, таких как сами RDF и RDF Schema, Dublin Core и DAML.
Код для создания ресурса и добавления свойств можно записать более компактно используя каскадный стиль:
Resource johnSmith = model.
createResource
(personURI
) .
addProperty
(VCARD.
FN, fullName
)
;
Работоспособный код для этого примера можно найти в директории /src-examples дистрибутива Jena Tutorial 1. В качестве упражнения возьмите этот код и измените его для того, чтобы создать вашу собственную VCARD.
теперь давайте добавим несколько дополнительных деталей к vcard, а заодно изучим некоторые новые возможности RDF и Jena.
В первом примере значением свойства был литерал. Свойства RDF могут также принимать другие ресурсы в качестве значений. Используя обычную технику RDF, этот пример демонстрирует как представить разные части имени Джона Смита:
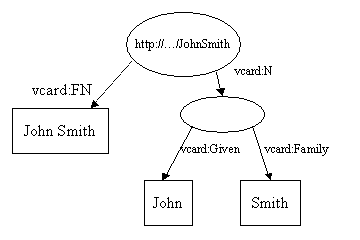
Здесь мы добавили новое свойство, vcard:N, чтобы представить структуру имени Джона Смита. Несколько вещей будут нам интересны в этой модели. Заметим, что свойство vcard:N принимает ресурс в качестве своего значения. Заметим, также, что эллипс, который представляет составное имя не имеет URI. такой узел называется Пустой Узел (Blank Node).
Код для создания этого примера опять очень прост. Сначала несколько определений и создание пустой модели.
// несколько определений
String personURI =
"http://somewhere/JohnSmith"
;
String givenName =
"John"
;
String familyName =
"Smith"
;
String fullName = givenName +
" " + familyName
;
// создание пустой модели Model model = ModelFactory.
createDefaultModel
(
)
;
// создание ресурса
// и добавление свойств в каскадном стиле Resource johnSmith = model.
createResource
(personURI
) .
addProperty
(VCARD.
FN, fullName
) .
addProperty
(VCARD.
N, model.
createResource
(
) .
addProperty
(VCARD.
Given, givenName
) .
addProperty
(VCARD.
Family, familyName
)
)
;
Рабочий код для этого примера Tutorial 2 можно найти в директории /src-examples дистрибутива Jena.
Утверждения (Statements)
Каждая дуга в Модели RDF называется утверждение (statement). Каждое утверждение предъявляет факт о ресурсе. Утверждение имеет три части:
- субъект — это ресурс из которого исходит дуга
- предикат — свойство, которым помечена дуга
- объект — ресурс или литерал на который указывает дуга
Утверждения иногда называют тройками, т.к. они состоя из трех частей.
Модель RDF представляет собой набор утверждений. Каждый вызов addProperty в Tutorial 2 добавлял еще одно утверждение к Модели. (так как Модель — это набор утверждений, добавление дубликатов утверждений не оказывает никакого эффекта). Интерфейс Model в Jena определяет метод listStatements(), который возвращает StmtIterator, подтип Iterator-а Jena, для прохода по всем утверждениям в Модели. StmtIterator имеет метод nextStatement(), который возвращает следуюжее утверждение (тоже, которое вернет next(), но уже приведенное к типу Statement). Интерфейс Statement) предоставляет методы для доступа к субъекту, предикату и объекту утверждения.
теперь мы используем этот интерфейс для того, чтобы расширить Tutorial 2 и включить в него просмотр всех созданных утверждений. Законченный код этого примера можно найти здесь: Tutorial 3.
// список утверждений в Модели StmtIterator iter = model.
listStatements
(
)
;
// вывод предиката, субъекта и объекта каждого утверждения
while
(iter.
hasNext
(
)
)
{
Statement stmt = iter.
nextStatement
(
)
;
// получить следующее утверждение Resource subject = stmt.
getSubject
(
)
;
// получить субъект Property predicate = stmt.
getPredicate
(
)
;
// получить предикат RDFNode object = stmt.
getObject
(
)
;
// получить объект
System .
out.
(subject.
toString
(
)
)
;
System .
out.
(
" " + predicate.
toString
(
) +
" "
)
;
if
(object
instanceof Resource
)
{
System .
out.
(object.
toString
(
)
)
;
}
else
{
// объект - литерал
System .
out.
(
" \"" + object.
toString
(
) +
"\""
)
;
}
System .
out.
println
(
" ."
)
;
}
так как объект утверждения может быть или ресурсом или литералом, метод getObject() возвращает объект как RDFNode, который является суперклассом и для Resource и для Literal. Реальный объект является или Resource-ом или Literal-ом, так что в коде используется instanceof для того чтобы определить действительный тип объекта и обработать его соответствующим образом.
После запуска эта программа должна вывести примерно следующее:
http://somewhere/JohnSmith http://www.w3.org/2001/vcard-rdf/3.0#N anon:14df86:ecc3dee17b:-7fff .
anon:14df86:ecc3dee17b:-7fff http://www.w3.org/2001/vcard-rdf/3.0#Family "Smith" .
anon:14df86:ecc3dee17b:-7fff http://www.w3.org/2001/vcard-rdf/3.0#Given "John" .
http://somewhere/JohnSmith http://www.w3.org/2001/vcard-rdf/3.0#FN "John Smith" .
теперь вы понимаете почему диаграммы Моделей понятнее. Если вы посмотрите внимательно, то вы заметите, что каждая строка состоит из трех полей представляющих субъект, предикат и объект соответствующего утверждения. Модель содержит четыре дуги, соответственно они представлены четырьмя утверждениями. «anon:14df86:ecc3dee17b:-7fff» — это внутренний идентификатор сгенерированный Jena. Нужно четко понимать, что это не URI. Это просто внутренняя метка, которую использует реализация Jena.
RDFCore Рабочая Группа консорциума W3C разработала аналогичную простую нотацию N-Triples. Что значит «нотация троек». Вы увидете в следующем разделе, что Jena имеет встроенные средства для записи RDF в N-Triples нотации.
Запись RDF
Jena имеет методы для чтения и записи RDF как XML. Они могут быть использованы для сохранения RDF модели в файле.
Tutorial 3 создает модель и сохраняет ее в форме N-Triples файла. Tutorial 4 модифицирует Tutorial 3 для вывода модели в форме RDF XML в стандартный поток вывода. Код, опять же очень, прост: model.write принимает OutputStream в качестве аргумента.
// теперь сохраним модель в форме XML в файл model.
write
(
System .
out
)
;
Вывод должен выглядить примерно так:
John Smith
John
Smith
Спецификации RDF указывают как представлять RDF в форме XML. Синтаксис RDF XML довольно сложен. Отсылаем читателя к примеру разработанному в Рабочей Группе RDFCore за более подробной информацией. Однако, давайте вкратце посмотрим как интерпретировать полученный документ.
Обычно RDF включается внутрь элемента . хотя этот элемент и не является обязательным, в тех случаях, когда есть другие способы указать, что данный XML представляет собой RDF документ, но обычно он присутствует. Элемент RDF определяет два пространства имен используемые в документе. Элемент описывает ресурс который определяется URI «http://somewhere/JohnSmith». Если атрибут rdf:about отсутствует, то этот элемент будет представлять пустой узел (Blank Node).
Элемент описывает свойство ресурса. Это свойство называется «FN» в пространстве имен vcard. RDF преобразует его в URI присоединяя «FN» к URI пространства имен. В результате получается «http://www.w3.org/2001/vcard-rdf/3.0#FN». Значением свойства является литерал «John Smith».
Элемент — является ресурсом. В данном случае ресурс представлен относительной URI ссылкой. RDF конвертирует такие ссылки в абсолютные URI присоединяя их к базовому URI текущегодокумента.
В данном RDF XML содержится ошибка, он не в поной мере отражает созданную нами Модель. Пустой узел в Модели получил URI ссылку. Он более не является пустым узлом. Синтаксис RDF/XML не позволяет представлять все RDF Модели, например он не позволяет отображать пустые узлы, которые являются объектом в двух утверждениях. «Простой» механизм записи, который мы использовали для записи этого RDF/XML, и не пытается записать правильно те модели, которые не могут быть отображены корректно. Он просто добавляет URI к каждому пустому узлу.
Jena имеет расширяемый интерфейс, который позволяет легко создавать новые механизмы записи для различных языков сериализации RDF. Указанный выше вызов запускает стандартный «простой» механизм записи. Jena также включает в себя более изощренный механизм записи RDF/XML который можно использовать указав еще один аргумент в вызове метода write():
// теперь сохраним в файле модель в форме XML model.
write
(
System .
out,
"RDF/XML-ABBREV"
)
;
Этот механизм записи, также называемый PrettyWriter, использует особенности сокращенного синтаксиса RDF/XML для более компактной записи Модели. Однако он не подходит для записи очень больших моделей, так как его производительность не слишком велика. Для того, чтобы записывать большие файлы, и сохранять при этом пустые узлы используйте формат N-Triples:
// теперь сохраним в файле модель в форме N-Triples model.
write
(
System .
out,
"N-TRIPLE"
)
;
таким образом мы получим выход аналогичный тому, что мы видели в Tutorial 3, что соответствует спецификации N-Triples.
Чтение RDF
Tutorial 5 демонстрирует чтение утверждений записанных в форме RDF XML. Вместе с этим уроком мы предоставляем небольшую базу данных бизнес карточек (vcard) в форме RDF/XML. Следующий код будет читать ее и выводить содержимое на консоль. Заметим, что это приложение требует наличие входного файла в текущей директории.
// создание пустой модели Model model = ModelFactory.
createDefaultModel
(
)
;
// используем FileManager для поиска входного файла
InputStream in = FileManager.
get
(
).
open
( inputFileName
)
;
if
(in ==
null
)
{
throw
new
IllegalArgumentException
(
"File: " + inputFileName +
" not found"
)
;
}
// читаем RDF/XML файл model.
read
(in,
""
)
;
// пишем на консоль model.
write
(
System .
out
)
;
Второй аргумент в вызове метода read() — URI, который будет использоваться для разрешения относительных URI. так как в тестовом файле нет никаких относительных URI, то можно оставить этот параметр пустым. После запуска Tutorial 5 выведет на консоль следующее:
Smith
John
John Smith
Sarah Jones
Matt Jones
Smith
Rebecca
Jones
Sarah
Jones
Matthew
Becky Smith
Управление Префиксами
явное определение префиксов
В предыдущем разделе мы видели, что XML декларирует префикс пространства имен vcard и использует его для сокращения записи URI. В то время как RDF использует только полностью квалифицированные URI, а не сокращенные формы, Jena позволяет конторолировать пространства имен используемые при выводе с помощью механизма отображения префиксов. Рассмотрим простой пример:
Model m = ModelFactory.
createDefaultModel
(
)
;
String nsA =
"http://somewhere/else#"
;
String nsB =
"http://nowhere/else#"
; Resource root = m.
createResource
( nsA +
"root"
)
; Property P = m.
createProperty
( nsA +
"P"
)
; Property Q = m.
createProperty
( nsB +
"Q"
)
; Resource x = m.
createResource
( nsA +
"x"
)
; Resource y = m.
createResource
( nsA +
"y"
)
; Resource z = m.
createResource
( nsA +
"z"
)
; m.
add
( root, P, x
).
add
( root, P, y
).
add
( y, Q, z
)
;
System .
out.
println
(
"# -- no special prefixes defined"
)
; m.
write
(
System .
out
)
;
System .
out.
println
(
"# -- nsA defined"
)
; m.
setNsPrefix
(
"nsA", nsA
)
; m.
write
(
System .
out
)
;
System .
out.
println
(
"# -- nsA and cat defined"
)
; m.
setNsPrefix
(
"cat", nsB
)
; m.
write
(
System .
out
)
;
Данный фрагмент выводит три набора RDF/XML используя три разных отображения префиксов. Первый, используемый по умолчанию, не указывает никаких префиксов кроме стандартных:
# -- no special prefixes defined
Можно видеть, что пространство имен rdf определено автоматически, так как оно необходимо, для таких тэгов как и . Определения пространств имен также необходимо для использования двух свойств: P и Q. Но, так как их пространства имен не были указаны в модели им присвоены вновь сгенерированные имена: j.0 и j.1.
Метод setNsPrefix(String prefix, String URI) определяет, что пространство имен URI можно сокращенно записать как prefix. Jena требует чтобы prefix был крректным именем пространства имен в XML, и, чтобы URI заканчивался не буквой. Механизм записи RDF/XML превратит это определение префикса в декларацию пространства имен XML и будет использовать его при выводе:
# -- nsA defined
Другие пространства имен все еще получают сконструированное имя, но имя nsA теперь используется в тэге свойства. Нет никакой необходимости как-то маипулировать переменными в коде для определения префиксов:
# -- nsA and cat defined
Оба префикса используются для вывода, так что атоматически сгенерированные префиксы более не нужны.
неявное определение префиксов
Аналогично тому, как Jena запоминает определения префиксов введенных с помощью вызова setNsPrefix, Jena схраняет и префиксы прочитанные из входных данных методом model.read().
Возьмите вывод полученный с помощью предыдущего фрагмента и сохраните его в файл расположенный скажем по адресу file:/tmp/fragment.rdf. Затем запустите код:
Model m2 = ModelFactory.
createDefaultModel
(
)
; m2.
read
(
"file:/tmp/fragment.rdf"
)
; m2.
write
(
System .
out
)
;
Вы увидете, что префиксы из входных данных сохранены и в выводе программы. Все префиксы записаны, даже те, которые нигде не используются. Вы можете удалить префикс с помощью вызова removeNsPrefix(String prefix) если вы не хотите видеть его в выходных данных.
так как N-Triples не имеют никаких средств для краткой записи URI, в этом формате управление префиксами никак не используется. Нотация N3, которая также поддерживается Jena, использует префиксы для краткой записи URI.
Jena поддерживает дополнительные операции для отображения префиксов, содержащихся в модели, такие как получение Java Map для существующих отображений, или добавление целой группы отображений за раз. Смотрите документацию на PrefixMapping для дополнительной информации.
Пакеты Jena RDF
Jena — это Java API для разработки приложений semantic web. Ключевой пакет для прикладного разработчика — это com.hp.hpl.jena.rdf.model. API определено в терминах интерфейсов, так что прикладной код может работать с разными реализациями без изменений. Этот пакет содержит интерфейсы для представления моделей, ресурсов, свойств, литералов, утверждений и всех остальных ключевых концепций RDF, а также ModelFactory для создания моделей. таким образом прикладной код остается независимым от реализации. Наилучшей практикой является использование интерфейсов вместо специфических реализаций везде, где это возможно.
Пакет com.hp.hpl.jena.tutorial содержит исходный код, для всех прмеров из этого руководства.
Пакеты com.hp.hpl.jena…impl содержат классы, которые могут быть использованы во многих реализациях. Например они определяют классы ResourceImpl, PropertyImpl, и LiteralImpl, которые могут быть использованы непосредственно или переопределены в разных реализациях. Приложения вряд ли будут использовать эти классы непосредственно. Например вместо того, чтобы создавать экземпляр класса ResourceImpl лучше использовать метод createResource соответствующей модели. В этом случае, если модель использует оптимизированную реализацию Resource, то не потребуется преобразование между двумя типами.
Навигация по Модели
До сих пор, мы имели дело, в основном, с созданием, чтением и записью RDF Моделей. Настало время научиться получать информацию содержащуюся в Модели.
Если мы имеем URI ресурса, то мы можем получить объект воспользовавшись методом Model.getResource(String uri). Этот метод вернет объект ресурса, если он содержится в Модели, или, если такого объекта в Модели нет, он создаст новый объект ресурса. Например: для того, чтобы получить ресурс Джона Смита из модели содержащейся в файле из Tutorial 5:
// получение ресурса vcard Джона Смита из модели Resource vcard = model.
getResource
(johnSmithURI
)
;
Интерфейс Resource определяет несколько методов для получения доступа к свойствам ресурса. Метод Resource.getProperty(Property p) возвращает свойство ресурса. Этот метод не следует обычным соглашениям аксессоров Java, так как тип возвращаемого объекта — Statement, а не Property как могло бы показаться. Получение утверждения целиком позволяет приложению получить доступ к значению свойства через методы аксессоры этого утверждения, которые возвращают объект утверждения. Например: для получения ресурса, который является значением свойства vcard:N:
// получение значения свойства N Resource name =
(Resource
) vcard.
getProperty
(VCARD.
N
) .
getObject
(
)
;
В общем случае, объект утверждения может быть ресурсом или литералом, так что код приложения, зная, что значение должно быть ресурсом приводит результат к соответствующему типу. Jena пытается предоставить методы специфические для соответствующих типов, чтобы приложению не приходилось делать преобразования типов, и чтобы проверку типов можно было бы сделать во время компиляции. так что приведенный выше код можно переписать более удобным способом:
// получение значения свойства N Resource name = vcard.
getProperty
(VCARD.
N
) .
getResource
(
)
;
Аналогично может быть получено литеральное значение:
// получение свойства имени
String fullName = vcard.
getProperty
(VCARD.
FN
) .
getString
(
)
;
В данном примере, ресурс vcard имеет только одно свойство vcard:FN и только одно свойство vcard:N. RDF допускает наличие нескольких экземпляров свойства у ресурса. Например Джон может иметь более одного псевдонима. Давайте дадим ему два:
// добавление двух псевдонимов в vcard vcard.
addProperty
(VCARD.
NICKNAME,
"Smithy"
) .
addProperty
(VCARD.
NICKNAME,
"Adman"
)
;
Как отмечалось ранее, Jena представляет RDF Модель как набор утверждений, так что добавление утверждения с субъектом, предикатом и объектом совпадающими с уже существующим в Модели утверждением не будет иметь никакого эффекта. Jena не определяет какой из двух псевдонимов присутствующих в Модели будет возвращен. Результат вызова vcard.getProperty(VCARD.NICKNAME) — неопределен. Jena вернет одно из значений, но не гарантирует даже того, что два последовательных вызова вернут тоже самое значение.
Если допустимо наличие нескольких значений свойства, тогда вызов метода Resource.listProperties(Property p) вернет указатель на итератор для перебора всех существующих значений. Этот итератор возвращает объекты типа Statement. так что мы можем просмотреть все псевдонимы следующим способом:
// инициализация вывода
System .
out.
println
(
"The nicknames of \"" + fullName +
"\" are:"
)
;
// перебор псевдонимов StmtIterator iter = vcard.
listProperties
(VCARD.
NICKNAME
)
;
while
(iter.
hasNext
(
)
)
{
System .
out.
println
(
" " + iter.
nextStatement
(
) .
getObject
(
) .
toString
(
)
)
;
}
Этот код можно найти в Tutorial 6. Итератор утверждеий iter позволяет обойти все утверждения с субъектом vcard и предикатом VCARD.NICKNAME, так что последовательно вызывая метод итератора nextStatement() мы можем получить все псевдонимы. Этот код выдает следующий результат:
The nicknames of
"John Smith" are: Smithy Adman
Все свойства ресурса могут быть получены с помощью вызова метода listProperties() без аргументов.
Запросы к Модели
В предыдущем разделе мы имели дело со случаем, когда мы знали URI интересующего нас ресурса. В этом разделе мы будем искать информацию внутри модели. Базовое API Jena поддерживает только ограниченное множество запросов. Для того, чтобы использовать более сложные запросы, обратитесь к возможностям языка запросов RDQL.
Метод Model.listStatements(), который позволяет перебрать все утверждения в модели — возможно самый грубый способ поиска информации в модели. Этот способ не рекомендуется использовать на больших моделях. Метод Model.listSubjects() — аналогичен, но возвращает итератор для перебора всех ресурсов у которых есть свойства, то есть которые являются субъектами в утверждениях.
Model.listSubjectsWithProperty(Property p, RDFNode o) возвращает итератор для прохода по всем ресурсам, которые имеют свойство p со значением o. Если мы предположим, что только ресурсы vcard имеют свойство vcard:FN, и что в наших данных, все такие ресурсы имеют это свойство, то мы можем найти все vcard следующим образом:
// перечисление всех vcard ResIterator iter = model.
listSubjectsWithProperty
(VCARD.
FN
)
;
while
(iter.
hasNext
(
)
)
{ Resource r = iter.
nextResource
(
)
; ...
}
Все эти методы запроса информации — всего лишь удобные обертки вокруг базового метода запроса model.listStatements(Selector s). Этот метод возвращает итератор для обхода всех утверждений в модели ‘удовлетворяющих’ селектору s. Интерфейс селектора спроектирован таким образом, чтобы предоставить возможность его расширять и модифицировать, но, на текущий момент, существует только одна его реализация — класс SimpleSelector из пакета com.hp.hpl.jena.rdf.model. Использование SimpleSelector — тот редкий случай в Jena, когда следует использовать специфический класс, а не интерфейс. Конструктор SimpleSelector принимает три аргумента:
Selector selector =
new SimpleSelector
(subject, predicate, object
)
такой селектор будет выбирать все утверждения, для которых субъект совпадает с subject, предикат — с predicate и объект с object. Если null, указан в какой-либо позиции, то он соответствует любому значению, иначе — значение должно совпадать с указанным ресурсом или литералом. (Два ресурса считаются равными (совпадающими) если они имеют эквивалентные URI или являются одним и тем же пустым узлом; два литерала овпадают если их компоненты равны друг другу). так:
Selector selector =
new SimpleSelector
(
null,
null,
null
)
;
будет перечислять все утверждения в Модели.
Selector selector =
new SimpleSelector
(
null, VCARD.
FN,
null
)
;
выберет все утверждения у которых VCARD.FN — предикат, вне зависимости от того, что используется в качестве субъекта или объекта. Существует упрощенная форма записи:
listStatements
( S, P, O
)
которая эквивалентна
listStatements
(
new SimpleSelector
( S, P, O
)
)
Следующий код, который вы можете найти в Tutorial 7 перечисляет полные имена всех бизнес карточек в базе данных.
// выбрать все ресурсы у которых есть свойство VCARD.FN ResIterator iter = model.
listSubjectsWithProperty
(VCARD.
FN
)
;
if
(iter.
hasNext
(
)
)
{
System .
out.
println
(
"The database contains vcards for:"
)
;
while
(iter.
hasNext
(
)
)
{
System .
out.
println
(
" " + iter.
nextStatement
(
) .
getProperty
(VCARD.
FN
) .
getString
(
)
)
;
}
}
else
{
System .
out.
println
(
"No vcards were found in the database"
)
;
}
В результате мы получим следующее:
The database contains vcards
for: Sarah Jones John Smith Matt Jones Becky Smith
В качестве очередного упражнения попробуйте переписать этот код для того, чтобы использовать SimpleSelector вместь listSubjectsWithProperty.
Давайте посмотрим, как реализовать более тонкое управление тем, какие утверждения выбирать. Можно создать класс унаследованный от SimpleSelector и реализовать в нем метод selects, в котором производится дополнительная фильтрация:
// выбрать все ресурсы у которых есть свойство VCARD.FN,
// значение которого заканчивается на "Smith" StmtIterator iter = model.
listStatements
(
new SimpleSelector
(
null, VCARD.
FN,
(RDFNode
)
null
)
{
public
boolean selects
(
Statement s
)
{
return s.
getString
(
).
endsWith
(
"Smith"
)
;
}
}
)
;
Этот пример использует замечательную возможность языка Java для переопределения метода по месту, в момент создания экземпляра класса. В данном случае, метод selects(…) проверяет, что полное имя заканчивается на «Smith». Важно заметить, что фильтрация по субъекту, предикату и объекту имеет место до того как будет вызван метод selects(…), так что дополнительная проверка будет производиться только над теми утверждениями, которые удовлетворяют фильтру.
Код этого примера можно найти в Tutorial 8. В результате запуска этой программы мы получим следующее:
The database contains vcards
for: John Smith Becky Smith
Вы можете подумать что:
// проделаем всю фильтрацию в методе selects StmtIterator iter = model.
listStatements
(
new SimpleSelector
(
null,
null,
(RDFNode
)
null
)
{
public
boolean selects
(
Statement s
)
{
return
(subject ==
null || s.
getSubject
(
).
equals
(subject
)
)
&&
(predicate ==
null || s.
getPredicate
(
).
equals
(predicate
)
)
&&
(object ==
null || s.
getObject
(
).
equals
(object
)
)
}
}
}
)
;
эквивалентно:
StmtIterator iter = model.
listStatements
(
new SimpleSelector
(subject, predicate, object
)
хотя функционально эти куски кода могут быть эквивалентными, первый — будет выдавать все утверждения в Модели и проверять каждое из них в отдельности, в то время как второй позволяет воспользоваться индексами, существующими в реализации, и за счет этого повысить производительность. Попробуйте запустить их на большой Модели и вы убедитесь в этом. только сначала сделайте себе чашечку кофе.
Операции над Моделями
Jena предоставляет три операции для манипулирования Моделями, как целым. Это обычные операции объединения, пересечения и разности.
Объединение двух Моделей представляет собой объединение всех утверждений из каждой Модели. Это одна из ключевых операций поддерживаемых RDF. Она позволяет соединять данные из разных источников. Рассмотрим следующие две Модели:
и 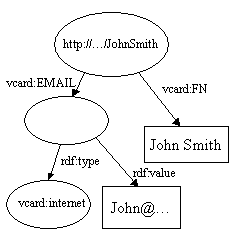
Когда они объединяются, то два узла http://…JohnSmith сливаются в один, и дубликат дуги vcard:FN опускается. В результате мы получим следующее:
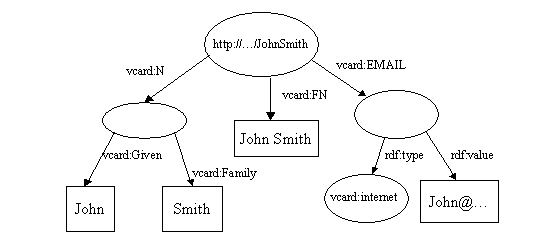
Посмотрим на код, который выполняет эту операцию (полную версию примера можно найти в Tutorial 9).
// читаем RDF/XML файлы model1.
read
(
new
InputStreamReader
(in1
),
""
)
; model2.
read
(
new
InputStreamReader
(in2
),
""
)
;
// соединяем Модели Model model = model1.
union
(model2
)
;
// печатаем Модель как RDF/XML model.
write
(system.
out,
"RDF/XML-ABBREV"
)
;
На выходе получаем следующее:
John@ somewhere.com
John
Smith
John Smith
Даже если вы не знакомы с деталями синтаксиса RDF/XML, должно быть очевидно, что Модели объединены так как мы ожидали. Пересечение и Разность Моделей может быть вычислена аналогично, с использованием методов .intersection(Model) и .difference(Model); см. difference и intersection Javadocs для получения дополнительной информации.
Контейнеры
RDF определяет специальный вид ресурсов для представления коллекций объектов. Эти ресурсы называются контейнеры. Элементами контейнера могут быть или литералы или ресурсы. Существует три типа контейнеров:
- BAG — неупорядоченная коллекция
- ALT — неупорядоченная коллекция преднозначенная для представления альтернатив
- SEQ — упорядоченная коллекция
Контейнер представляется ресурсом. Этот ресурс имеет свойство rdf:type значением которого должно быть rdf:Bag, rdf:Alt или rdf:Seq; или подкласс одного из этих значений в зависимости от типа контейнера. Первый элемент контейнера — это значение свойства контейнера rdf:_1, второй элемент контейнера — это значение свойства контейнера rdf:_2 и так далее. Свойства rdf:_nnn называются порядковыми свойствами.
Например: Модель простой коллекции бизнес карточек Смита может выглядить примерно так:
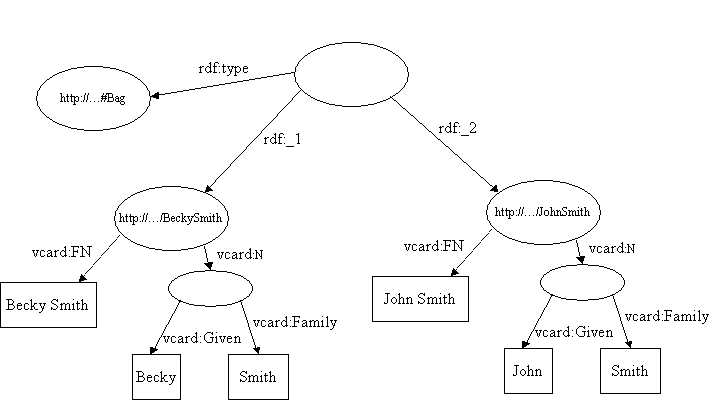
хотя элементы контейнера BAG представлены свойствами rdf:_1, rdf:_2 и т.д. порядок этих свойств не имеет значения. Мы можем поменять значения свойств rdf:_1 и rdf:_2 но результирующая Модель будет представлять туже самую информацию.
Контейнеры ALT предназначены для представления альтернатив. Например: предположим, что ресурс представляет программный продукт. Он может иметь свойство указывающее откуда его можно получить. Значением этого свойства может быть ALT коллекция содержащая различные сайты, откуда можно загрузить данный продукт. Контейнеры ALT неупорядоченны, за исключением свойства rdf:_1, которое имеет особое значение. Это свойство определяет выбор по умолчанию.
хотя контейнеры могут быть обработаны с использованием базовых механизмов для работы с ресурсами и свойствами, Jena имеет явные интерфейсы и классы реализаций для их обработки. Не слишком хорошая идея иметь объект для манипулирования контейнером, и в тоже время модифицировать состояние этого контейнера используя методы более низкого уровня.
Давайте изменим Tutorial 8 чтобы создать такую коллекцию:
// создаем коллекцию Bag smiths = model.
createBag
(
)
;
// выбираем все ресурсы у которых свойство VCARD.FN имеет
// значение оканчивающееся на "Smith" StmtIterator iter = model.
listStatements
(
new SimpleSelector
(
null, VCARD.
FN,
(RDFNode
)
null
)
{
public
boolean selects
(
Statement s
)
{
return s.
getString
(
).
endsWith
(
"Smith"
)
;
}
}
)
;
// добавляем Смита в коллекцию
while
(iter.
hasNext
(
)
)
{ smiths.
add
(iter.
nextStatement
(
).
getSubject
(
)
)
;
}
Если мы выведем эту коллекцию, то мы получим следующее:
...
так выглядит представление ресурса коллекции типа BAG.
Интерфейс контейнера предоставляет итератор для прохода по содержимому коллекции:
// печать елементов коллекции NodeIterator iter2 = smiths.
iterator
(
)
;
if
(iter2.
hasNext
(
)
)
{
System .
out.
println
(
"The bag contains:"
)
;
while
(iter2.
hasNext
(
)
)
{
System .
out.
println
(
" " +
(
(Resource
) iter2.
next
(
)
) .
getProperty
(VCARD.
FN
) .
getString
(
)
)
;
}
}
else
{
System .
out.
println
(
"The bag is empty"
)
;
}
В результате мы получим следующее:
The bag contains:
John Smith
Becky Smith
Код примера можно найти здесь: Tutorial 10. Он представляет собой два вышеуказанных фрагмента соединенные вместе.
Классы Jena предлагают методы для манипулирования контейнерами, в том числе для добавления элементов в конец коллекции, для вставки элементов в середину коллекции и для удаления элемента из коллекции. Классы контейнеров Jena гарантируют, что список порядковых свойств начинается с rdf:_1 и является непрерывным. Рабочая Группа RDFCore ослабила это ограничение, и теперь допускаются частично заполненые контейнеры. Поэтому эта реализация может быть изменена в будущем.
Еще о литералах и типах Данных
литералы RDF — это не просто строки. литералы могут содержать метку языка для того, чтобы указывать на каком языке указан данное значение. литерал «chat» с меткой Английского языка считается отличающимся от литерала «chat» с меткой Французского. Это, несколько странное, поведение является следствием первоначального синтаксиса RDF/XML.
Более того, на самом деле существуют два сорта литералов. В одном, строковый компонент — это просто обычная строка. В другом, предполагается, что строковый компонент — это правильно структурированный фрагмент XML. Когда RDF Модель записывается в форме RDF/XML, то используется специальная конструкция с атрибутом parseType=’Literal’.
В Jena эти атрибуты могут быть установлены при создании литерала, например см. в Tutorial 11:
// создание ресурса Resource r = model.
createResource
(
)
;
// add the property r.
addProperty
(RDFS.
label, model.
createLiteral
(
"chat",
"en"
)
) .
addProperty
(RDFS.
label, model.
createLiteral
(
"chat",
"fr"
)
) .
addProperty
(RDFS.
label, model.
createLiteral
(
"chat",
true
)
)
;
// печать Модели model.
write
(system.
out
)
;
выводит
chat
chat
chat
Для того, чтобы два литерала считались равными, они должны быть либо оба XML литералами, или оба простыми литералами. В дополнение, они оба не должны иметь меток языка, или эти метки должны быть одинаковыми. Для простых литералов строки должны быть равными. XML литералы имеют два понятия равенства. В простом случае литералы считаются равными, когда выполняются все приведенные выше условия и строки литералов также равны. В более сложном случае литералы считаются равными, когда совпадают канонические формы из строк.
Интерфейсы Jena также поддерживают типизированные литералы. Устаревшая практика (показанная ниже) заключалась в том, чтобы трактовать типизированные литералы как сокращенные записи для строк: типизированные значения преобразовывались обычным для Java способом в строки, и эти строки сохранялись в Модели. Например: попробуем (заметим, что для простых литералов мы можем опустить вызов model.createLiteral(…):
// создание ресурса Resource r = model.
createResource
(
)
;
// добавление свойств r.
addProperty
(RDFS.
label,
"11"
) .
addProperty
(RDFS.
label,
11
)
;
// сохранение Модели model.
write
(system.
out,
"N-TRIPLE"
)
;
В результате получаем:
_:A...
"11".
так как оба литерала представляют собой просто строки «11», то только одно утверждение добавилось.
Рабочая Группа RDFCore определила механизмы для поддержки типов данных в RDF. Jena поддерживает их через механизмы типизированных литералов; но они не рассматриваются в данном руководстве.
Глоссарий
Пустой Узел Представляет ресурс, но не указывает для него URI. Пустые Узлы ведут себя как квалифицированные пременные в логике первого порядка. Дублинское Ядро (Dublin Core) Стандарт для метаданных о ресурсах интернета. Более подробную информацию можно найти на сайте Dublin Core. Литерал Строка символов, которая может быть значением свойства. Объект Часть тройки, которая является значением утверждения. Предикат Часть тройки, которая является свойством. Свойство Свойство — это атрибут ресурса. Например: DC.title — это свойство, так же как и RDF.type. Ресурс Некая сущность. Он может быть ресурсом в интернете, таким как веб-страница, или он может быть конкретным физическим объектом, таким как дерево или машина. Он может быть абстрактным понятием таким как шахматы или футбол. Ресурсы иденитифицируются с помощью URI. Утверждение Дуга в RDF Модели, обычно интерпретируется как факт. Субъект Ресурс из которого исходит дуга в RDF Модели. Тройка Структура состоящая из субъекта, предиката и объекта. Синоним утверждения.
Сноски
- Идентификатор RDF ресурса может включать указатель фрагмента, например: http://hostname/rdf/tutorial/#ch-Introduction, так что, строго говоря, RDF ресурс идентифицируется URI ссылкой.
- Кроме того, что литераты являются строкой символов, они могут иметь необязятельную метку языка, на котором представлена строка. Например: литерал «two» может иметь языковую метку «en» для Английского и литерал «deux» может иметь языковую метку «fr» для Французского языка.
RDF Файлы
Здесь вы можете закачать RDF файлы использованные в примерах
vc-db-1.rdf
vc-db-2.rdf
vc-db-3.rdf
vc-db-4.rdf